Februar 2, 2026


Sie sind ein professioneller Übersetzer ins Deutsche. Barry Devlin und Paul Murphy, zwei IBM-Europe-Ingenieure, versuchten 1986 ein Problem zu lösen, das die großen Konzerne jener Zeit beschäftigte: Betriebsdaten waren vorhanden, aber daraus Management-Analytik zu gewinnen war praktisch unmöglich. Transaktionssysteme speicherten den aktuellen Geschäftszustand, konnten aber keine Fragen nach dem „Warum“ oder „Was als Nächstes kommt“ beantworten. Devlin und Murphy entwickelten eine interne Architektur für IBM EMEA und veröffentlichten 1988 einen Artikel, der erstmals das Konzept des „Business Data Warehouse“ beschrieb.
Der Begriff, der zuvor nicht existierte, wurde innerhalb weniger Jahre zum Industriestandard.
Fast vierzig Jahre später ist das Problem immer noch nicht verschwunden – es hat lediglich seinen Maßstab geändert. Anstelle isolierter Mainframes haben Unternehmen heute CRMs, ERPs, Marketingplattformen, Produktionssysteme und Dutzende von Excel-Dateien, die „vorübergehend“ zum Hauptwerkzeug der Analytik geworden sind. Daten sind überall vorhanden, aber die Antwort auf eine einfache analytische Frage erfordert manchmal drei Tage Arbeit in der Finanzabteilung.
Im Folgenden analysieren wir, wie ein modernes Data Warehouse in der Ukraine aufgebaut ist: Wann wird es für ein Unternehmen zur Notwendigkeit und wie sieht dieser Weg in der Praxis aus?
Was ist ein Data Warehouse und wie unterscheidet es sich von einer Datenbank?
Jedes Unternehmen hat irgendwo seine Daten, aber die Hauptfrage ist, wozu diese Daten überhaupt benötigt werden. CRMs oder ERPs sind auf eine sehr einfache Aufgabe ausgelegt: schnell etwas zu erfassen und es genauso schnell wiederzufinden. Zum Beispiel öffnet ein Manager einen Kunden und erhält in Sekundenschnelle Informationen. Ein Geschäft wird abgeschlossen und das System zeichnet es auf.
Und das scheint perfekt zu sein … bis zu dem Moment, in dem eine Frage einer anderen Ebene auftaucht:
„Was passiert mit der Marge nach Kategorien in den letzten zwei Jahren, wenn man sie nach Regionen und Vertriebskanälen aufschlüsselt?“
Eine operative Datenbank ist auf eine solche Frage nicht ausgelegt. Sie entweder denkt zu lange nach, blockiert die Arbeit anderer Benutzer oder liefert Daten, die dennoch manuell zusammengeführt werden müssen.
Ein Data Warehouse ist eine separate analytische Umgebung innerhalb der Datenarchitektur, in die Daten aus verschiedenen Systemen gelangen, bereinigt und in eine einheitliche Struktur für die weitere Analyse überführt werden.
DWH vs. OLTP vs. Data Lake
Drei Konzepte, die häufig verwechselt werden:
| Merkmal | OLTP | Data Warehouse | Data Lake |
|---|---|---|---|
| Zweck | Operative Transaktionen | Analytische Abfragen | Speicherung von Rohdaten in beliebigen Formaten |
| Datenstruktur | Normalisiert | Denormalisiert, für Lesezugriffe optimiert | Beliebig (strukturiert, halbstrukturiert, unstrukturiert) |
| Typische Benutzer | Manager, Sachbearbeiter | Analysten, Führungskräfte | Data Scientists, Data Engineers |
| Datenhorizont | Aktueller Zustand | Jahre an Historie | Unbegrenzt |
| Systembeispiele | SAP, Salesforce | BigQuery, Snowflake, Redshift | AWS S3, Azure Data Lake |
Kurz gesagt: OLTP beantwortet die Frage „Was passiert gerade?“, DWH beantwortet „Warum passiert es und was kommt als Nächstes?“, und im Data Lake werden große Mengen an Rohdaten in verschiedenen Formaten für die spätere Verarbeitung gespeichert. Data Lake und analytisches Data Warehouse konkurrieren nicht miteinander: In ausgereiften Architekturen koexistieren sie – der Lake als Schicht für Rohdaten, das DWH als strukturierte Analytik darüber.
Wann benötigt ein Unternehmen ein Data Warehouse?
Es gibt keine universelle Umsatzschwelle oder eine bestimmte Anzahl von Systemen, nach der ein DWH erforderlich ist. Aber es gibt konkrete Symptome:
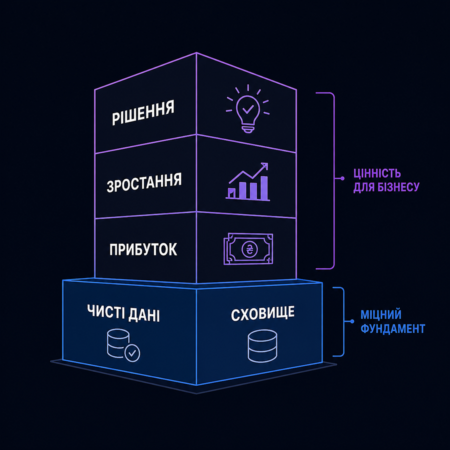
Ebenen: Staging → Core → Data Mart
Ein modernes analytisches Data Warehouse wird schichtweise aufgebaut, wobei jede Schicht eine klare Rolle und klare Verantwortungsgrenzen hat.
Staging (Bronze-Ebene) – die erste Ebene, auf der die Daten so landen, wie sie aus den Quellsystemen kommen: ohne Transformationen, ohne Bereinigung, ohne Geschäftslogik. Dies ist die Absicherung: Falls in den nächsten Phasen etwas schiefgeht, besteht die Möglichkeit, zum Original zurückzukehren und den Prozess neu zu starten.
Core (Silber-Ebene) – hier findet die eigentliche Hauptarbeit statt. Die Daten werden von Duplikaten und technischen Artefakten bereinigt, auf einheitliche Formate gebracht, mit Stammdaten angereichert und untereinander verknüpft. Der Kunde aus dem CRM und der Kunde aus dem ERP werden zu einem einzigen Datensatz mit einer eindeutigen Kennung. Die Produktposition aus verschiedenen Systemen erhält eine vereinheitlichte Bezeichnung. Dies ist die eigentliche Single Source of Truth.
Data Mart (Gold-Ebene) – fachbereichsspezifische Datenmärkte, die auf konkrete analytische Aufgaben optimiert sind: Finanz-Data-Mart für den CFO, Marketing-Data-Mart für den CMO, operativer Data-Mart für die Produktion. Abfragen werden hier schnell ausgeführt, da die Daten bereits für bestimmte Fragestellungen aggregiert sind.
Die dreistufige Architektur bietet zwei Dinge gleichzeitig: Stabilität – Veränderungen in den Quellsystemen zerstören nicht die Analytik, und Flexibilität – neue Data Marts können hinzugefügt werden, ohne das Fundament umbauen zu müssen.
ETL (Extract → Transform → Load): Der klassische Ansatz, bei dem Daten zuerst aus den Quellen extrahiert, auf einem separaten Server transformiert und erst dann in das Data Warehouse geladen werden. Dieser Ansatz funktionierte gut in der Ära teurer Cloud-Ressourcen und geringer Datenmengen.
ELT (Extract → Load → Transform): Der moderne Ansatz, bei dem Daten zuerst im Rohzustand in das Data Warehouse geladen werden und die Transformationen dann innerhalb des Data Warehouse stattfinden. Dies wurde durch Cloud-Plattformen mit ausreichender Rechenleistung für Transformationen direkt auf Warehouse-Ebene ermöglicht.
| Merkmal | ETL | ELT |
|---|---|---|
| Ort der Transformation | Externer Server | Innerhalb des DWH |
| Geeignet für | Legacy-Systeme, strenge Datensicherheitsanforderungen | Cloud-Plattformen, große Datenmengen |
| Entwicklungsgeschwindigkeit | Langsamer | Schneller |
| Kosten | Separater ETL-Server | Abhängig vom Rechenvolumen in der Cloud |
Für die meisten neuen Projekte wird heute ELT gewählt. Cloud-Plattformen machen es oft einfacher zu implementieren und zu skalieren, aber die Kosten hängen von der Effizienz der Abfragen und dem Verarbeitungsvolumen ab. Klassische ETL-Prozesse bleiben dort relevant, wo eine Legacy-Infrastruktur besteht oder strenge Anforderungen gelten, welche Daten die Unternehmensnetzgrenzen verlassen dürfen.
Top Cloud-DWH-Plattformen
Die Wahl der Plattform ist eine der Schlüsselentscheidungen, die später nur schwer rückgängig zu machen ist. Auf dem Markt für Cloud-DWH hat sich ein klarer Kreis von Marktführern gebildet: BigQuery und Snowflake werden in der Ukraine am häufigsten als grundlegende Optionen betrachtet, neben Redshift und Azure Synapse.
Google BigQuery
BigQuery ist eine serverlose Plattform von Google, bei der kein Cluster-Management oder eine Kapazitätsplanung erforderlich ist: Ressourcen werden automatisch für jede einzelne Abfrage zugewiesen. Sie basiert auf der eigenen Dremel-Engine, die parallele Spaltenabfragen über Tausende von Knoten gleichzeitig ausführt.
Vorteile: minimaler operativer Overhead, native Integration in das Google-Ökosystem (Looker Studio, Vertex AI, Google Analytics), Zahlungsmodell nach tatsächlich verarbeiteten Daten. Praktisch für ungleichmäßige Lasten.
Einschränkungen: Das On-Demand-Modell kann bei nicht optimierten Abfragen zu unvorhersehbaren Kosten führen. Erfordert Disziplin beim Schreiben von SQL. Bindung an Google Cloud.
Geeignet für: Unternehmen mit ungleichmäßiger Last, Projekte in Google Cloud, Teams ohne dedizierten Infrastrukturadministrator.
Snowflake
Snowflake basiert auf der Idee der vollständigen Trennung von Speicher und Rechenleistung, die unabhängig voneinander skaliert werden können. Die Plattform wird auf AWS, Azure oder Google Cloud betrieben und ist somit eine multi-cloudfähige Lösung ohne Bindung an einen bestimmten Anbieter.
Vorteile: Multi-Cloud-Fähigkeit, bequemer Datenaustausch zwischen Organisationen über den Snowflake Marketplace, verwaltetes Kostenmodell durch Virtual Warehouses mit flexibler Skalierung.
Einschränkungen: Höhere Grundkosten im Vergleich zu BigQuery bei geringen Volumina. Erfordert eine Planung der Größe der Virtual Warehouses entsprechend der Last.
Geeignet für: große Konzerne, Multi-Cloud-Umgebungen, Unternehmen mit Bedarf an Datenaustausch zwischen Geschäftsbereichen.
Amazon Redshift
Redshift ist die Lösung von AWS, tief integriert in das Amazon-Ökosystem: S3, Glue, SageMaker, QuickSight. Es existiert in zwei Varianten: klassisch provisioned und neuer serverless mit automatischer Skalierung.
Vorteile: Ausgereifte Werkzeuge für ETL-Prozesse über AWS Glue, breite Community, zahlreiche Integrationen innerhalb des AWS-Ökosystems.
Einschränkungen: Die klassische Variante erfordert eine Cluster-Planung und manuelles Management bei Laständerungen. Serverless adressiert einen Teil dieser Einschränkungen.
Geeignet für: Unternehmen, deren Infrastruktur bereits auf AWS läuft, Projekte mit stabiler und vorhersehbarer Last.
Microsoft Azure Synapse Analytics
Azure Synapse vereint auf einer Plattform DWH, Datenintegration und Big-Data-Analytik. Für Unternehmen in einer Microsoft-Umgebung bedeutet dies eine native Zusammenarbeit mit Power BI, Azure Active Directory und Microsoft Fabric ohne zusätzliche Integrationsschichten.
Vorteile: Einheitliche Umgebung für SQL-Abfragen und Spark-Berechnungen, tiefe Integration mit Power BI, vertraute Oberfläche für Teams im Azure-Ökosystem.
Einschränkungen: Der größere Funktionsumfang bedeutet gleichzeitig eine höhere Konfigurationskomplexität. Für kleinere Projekte kann es eine überdimensionierte Lösung sein.
Geeignet für: Unternehmen in einer Microsoft-Konzernumgebung, Projekte bei denen Power BI das Hauptvisualisierungswerkzeug ist.
British American Tobacco – ein multinationales Unternehmen mit Präsenz in über 180 Ländern und mehr als 50.000 Mitarbeitern. Der Maßstab des Geschäfts bedeutet einen Maßstab der Daten: Dutzende Quellen, Tausende von Kennzahlen, mehrere analytische Teams mit unterschiedlichen Anforderungen.
Aufgabenstellung
In der ersten Phase führte das Team ein Audit der bestehenden Power-BI-Berichte durch und identifizierte Probleme bei Berechnungen und der Nutzung der Plattformtools. Vor der Zusammenarbeit mit IWIS funktionierte die analytische Berichterstattung von BAT instabil: Berichte waren zeitweise nicht verfügbar, Kennzahlen wurden mit Verzögerungen neu berechnet, und die Systemgeschwindigkeit führte zu Beschwerden. Die Diagnose ergab ein systemisches Problem: Die Daten wurden ohne Zwischenspeicherung transportiert und transformiert. Tatsächlich startete jede Abfrage an Power BI einen vollständigen Zyklus der Extraktion und Transformation von Daten aus den Quellen in Echtzeit. Jeder Fehler in einem beliebigen Schritt führte dazu, dass der Bericht einfach nicht geöffnet werden konnte.
Ein separates Problem war das Fehlen einer Orchestrierungsschicht für ETL-Prozesse: Niemand kontrollierte weder die Verbindung zu den Quellen, noch die tatsächliche Ausführung der Ladeprozesse, noch die Ausgabedatenqualität. Das System funktionierte wie eine Black Box.
Architekturlösung
Das IWIS-Team entwickelte mehrere Architekturvarianten, die jeweils den Aufbau eines Business-Data-Warehouse vorsahen, jedoch mit unterschiedlichen Tools. Der Kunde wählte die optimale Plattform unter Berücksichtigung der Unternehmensinfrastruktur.
Die Umsetzung umfasste zwei Ebenen:
Bronze-Layer (Rohdaten) – Für jede Quelle wurden Extraktionsmechanismen mit automatischer Speicherung der Rohdaten eingerichtet. Die Daten werden nicht mehr live transformiert, sondern zunächst unverändert abgelegt.
Silver-Layer (bereinigte Daten) – Ein separater Transformationsprozess bereinigt und strukturiert die Daten aus der Bronze-Ebene. Power BI greift nicht mehr direkt auf die Quellen zu, sondern arbeitet mit der bereits aufbereiteten Ebene.
Zusätzlich wurde ein infologisches Datenmodell erstellt: eine Beschreibung aller wichtigen Entitäten, ihrer Beziehungen und der Datenflüsse zwischen den Systemen. Dies vereinfachte die spätere Wartung und wurde zur Grundlage für die Skalierung.
Die wichtigste Komponente der Architektur ist der Orchestrierungsmechanismus. Das System kontrolliert die Ausführung jeder ETL-Aufgabe nach Zeitplan, vergleicht die Dateninkremente zwischen der Bronze-Ebene und der Quelle auf parallele Weise (unabhängig vom Extraktionsprozess selbst) und sendet bei Abweichungen oder Fehlern automatisch Benachrichtigungen per E-Mail und Telegram.
Ergebnisse
Das Team von IWIS und BAT durchlief den Weg von instabiler Berichterstattung zu einer vollwertigen zweistufigen Data-Warehouse-Architektur innerhalb von 12 Monaten. Konkrete Ergebnisse:
Die Gold-Ebene (Data Mart) wurde zum Zeitpunkt des Projektabschlusses nicht implementiert, da die bestehenden Anforderungen durch die Silver-Ebene abgedeckt waren. Die Architektur ist jedoch so konzipiert, dass die Hinzufügung der Gold-Ebene keine Umgestaltung der vorherigen Schichten erfordert.
Wenn es um die Entwicklung eines Data Warehouses geht, ist die Frage nach den Kosten eine der ersten. Und die Antwort ist immer dieselbe: Es kommt darauf an. Aber es gibt Orientierungspunkte, die helfen, ein realistisches Budget zu erstellen.
Die Entwicklungskosten setzen sich aus mehreren Komponenten zusammen:
Analyse und Architektur-Design: Die Discovery-Phase, in der das Team die Datenquellen, deren Qualität, Struktur und Beziehungen untersucht, das infologische Modell erstellt und die technische Lösung ausarbeitet. Diese Phase zu überspringen und sofort mit dem Coden zu beginnen, ist der häufigste Fehler, der bei Nacharbeiten teuer zu stehen kommt.
Entwicklung und Konfiguration: Aufbau der Warehouse-Ebenen, Einrichtung der ETL/ELT-Prozesse, Orchestrierung, Datenqualitätskontrolle. Der größte Teil des Budgets.
Plattformlizenzen: Abhängig von der gewählten Lösung. Cloud-Plattformen (BigQuery, Snowflake, Redshift, Azure Synapse) arbeiten nach dem Pay-as-you-go-Modell, daher sind die Anfangskosten gering, steigen aber mit dem Datenvolumen und der Anzahl der Abfragen.
Wartung und Weiterentwicklung: Nach dem Start benötigt das System Monitoring, Updates und das Hinzufügen neuer Quellen oder Data Marts.
Die Schätzungen basieren auf der Praxis des ukrainischen Marktes und globalen Benchmarks, da die meisten DWH-Projekte mit internationalen Cloud-Plattformen realisiert werden. Hier sind ungefähre Budgetorientierungen:
| Szenario | Umfang | Budgetrahmen |
|---|---|---|
| Basis-Start | 2–5 Quellen, Basisdatenmodell, ELT, einfache Berichterstattung | 15.000–30.000 $ |
| Mittel | 5–15 Quellen, Datenbereinigung, mehrere Data Marts, stabile ETL-Prozesse | 30.000–80.000 $ |
| Groß | 15+ Quellen, komplexe Logik, Data Governance, Integrationen, Skalierung | 80.000–200.000 $+ |
Diese Zahlen sind ein Ausgangspunkt. Die tatsächlichen Kosten werden nach der Discovery-Phase bestimmt, wenn die Qualität und Struktur der Quelldaten bekannt sind. Genau das kann das Budget entweder verringern oder um ein Vielfaches erhöhen. Hier treten die häufigsten Überraschungen auf: Ein Legacy-ERP-System mit einer zehn Jahre alten Dokumentation oder Daten in Formaten, von denen niemand zuvor gesprochen hat.
Häufige Fehler beim Aufbau eines Data Warehouse
Die meisten Probleme in DWH-Projekten sind organisatorischer oder architektonischer Natur. Hier sind die häufigsten:
Ausgelassene Discovery-Phase: Das Team beginnt mit der Entwicklung, ohne die Datenquellen, deren Qualität und die Geschäftslogik vollständig zu verstehen. Die Folge sind Nacharbeiten in späteren Phasen, die ein Vielfaches der ursprünglichen Analyse kosten.
Fehlender Datenverantwortlicher (Data Owner): Ein DWH ist eine Infrastruktur, die ständige Aufmerksamkeit erfordert. Wenn das Unternehmen keine Person hat, die für die Qualität und Aktualität der Daten verantwortlich ist, degradiert das System allmählich.
Der Versuch, alles auf einmal zu bauen: Der Wunsch, ein „perfektes Warehouse“ auf Anhieb zu schaffen, führt zu langen Projekten ohne Zwischenergebnisse. Der richtige Ansatz ist iterativ: Eine Basisarchitektur starten, einen Mehrwert schaffen, dann weiterentwickeln.
Ignorieren der Qualität der Eingangsdaten: „Garbage in, garbage out“ ist eine wörtliche Beschreibung dessen, was passiert, wenn die Quelldaten nicht validiert werden. Analytik mit schmutzigen Daten ist schädlich, weil sie ein falsches Vertrauen in die Zahlen erzeugt.
Plattformwahl vor dem Verständnis der Anforderungen: Die Plattform sollte sich nach der Architektur und den Anforderungen richten, nicht umgekehrt.
Wenn die Antwort auf die meisten Fragen „Nein“ lautet, sollte man mit einer Datenprüfung und der Festlegung der Anforderungen beginnen. Genau das ist der erste Schritt in einem gut durchdachten DWH-Projekt.
IWIS ist auf den Aufbau von Analyseinfrastrukturen für Unternehmen spezialisiert: von der Prüfung der Datenquellen bis hin zu einem vollwertigen Analysedatenlager mit ETL-Prozessen und BI-Berichten. Zu unseren Kunden zählen zahlreiche Unternehmen unterschiedlicher Größe, die den Weg von verstreuten Daten zu einer einzigen Quelle der Wahrheit zurückgelegt haben.
Wenn Sie sich in diesem Artikel wiedererkennen, wenden Sie sich an uns für eine kostenlose Beratung zur Datenarchitektur. Wir analysieren Ihre Infrastruktur und schlagen konkrete nächste Schritte vor.