2 Лютого, 2026

Коли Netflix вирішував, вкладати чи не вкладати 100 млн $ у “Картковий будинок”, у них не було пілотного епізоду, не було фокус-груп і не було гарантій. Але були дані: підписники, що дивились британський оригінал, майже завжди дивились фільми Девіда Фінчера. І майже завжди дивились їх до кінця. А ті, хто любив Фінчера, стабільно обирали Кевіна Спейсі. Три точки перетину на діаграмі Венна – і рішення прийняте. Алгоритм не гарантував хіт, але прибрав із рівняння сліпу ставку. Це і є прогнозна аналітика бізнесу в дії: структурована робота з даними про майбутнє.
Часто компанії, які вже впровадили аналітику, працюють із минулим: який був продаж у жовтні, скільки клієнтів відвалилось у кварталі, де впала маржа. Це корисно, але це ретроспектива. Прогнозна аналітика зсуває фокус вперед: що станеться наступного місяця, хто з клієнтів іде, яка категорія товарів може просісти. Тобто Predictive analytics в Україні для багатьох компаній починається з простого питання: що буде з попитом, клієнтами або виручкою в найближчі місяці.
Зручно розуміти аналітику як три рівні зрілості, де кожен наступний дає більше важелів для рішень:
| Рівень | Що запитує | Що дає |
|---|---|---|
| Descriptive (описова) | Що сталося? | Звіти, дашборди, KPI за минулий період |
| Predictive (прогнозна) | Що станеться? | Моделі прогнозу: попит, відтік, виручка |
| Prescriptive (приписова) | Що робити? | Рекомендації: знизити ціну, запустити retention-кампанію, поповнити склад |
Більшість українського бізнесу сьогодні знаходиться на першому рівні, і це вже добре. Дашборди і звіти дають огляд того, що відбувається прямо зараз, але щойно бізнес хоче не просто фіксувати ситуацію, а керувати нею на випередження – потрібен перехід до predictive. BI пояснює минуле, predictive analytics працює з майбутнім: що станеться і що з цим робити вже зараз.
Якщо хоча б два пункти резонують, компанія вже переросла описову аналітику.
Прогнозні моделі можна будувати під що завгодно: від погодинного завантаження кол-центру до ймовірності шлюбу на виробництві. Але якщо мета – швидко побачити окупність, є чотири напрямки, де методи прогнозування дають найбільш відчутний і вимірюваний результат.
Для будь-якого бізнесу з товарними залишками надлишок і дефіцит – це заморожені або втрачені гроші. На практиці прогноз попиту (аналітика продажів, сезонності, залишків і зовнішніх факторів) допомагає відповісти на дуже прикладне питання: скільки товару виробити, закупити або перемістити між складами. Прогноз попиту на основі ML-моделей враховує також зовнішні фактори: погоду, свята, рекламну активність, навіть поведінку конкурентів. У результаті склад поповнюється заздалегідь там, де буде попит, і не затоварюється там, де його не буде.
Churn prediction – одна з найпопулярніших задач машинного навчання в бізнесі, і не випадково: утримати клієнта дешевше, ніж залучити нового, а модель дає час діяти до того, як рішення прийняте.
Модель відтоку аналізує поведінкові сигнали: зменшення частоти покупок, падіння середнього чека, відсутність реакції на комунікації, зміна патерну використання продукту. На виході – список клієнтів із найвищою ймовірністю відходу і рекомендований тип втручання для кожного сегмента.
Для підписних сервісів, банків, телекому і будь-якого бізнесу з регулярними транзакціями churn prediction окупається вже в перші місяці після впровадження.
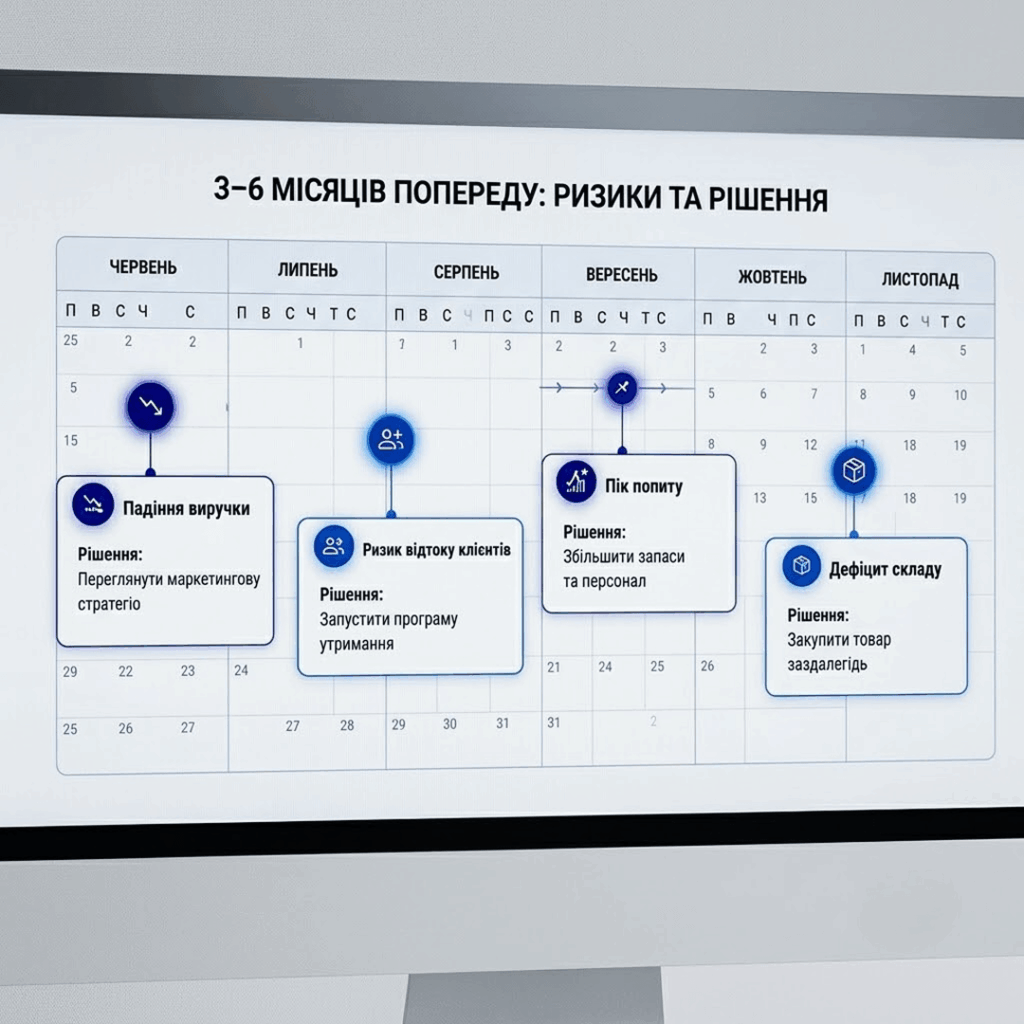
Прогнозування виручки на 3-6 місяців вперед дає розуміння діапазону: оптимістичний сценарій, реалістичний, стресовий. Такий підхід дозволяє фінансовому директору заздалегідь бачити касові розриви, керувати платіжним календарем і не займатися пожежним фандрейзингом у момент, коли криза вже настала.
ML-модель враховує сезонність, pipeline угод із CRM, ринкові тренди і навіть поведінку конкретних менеджерів з продажів: хто зазвичай виконує план, а хто системно переоцінює воронку.
Скоринг – це прогноз продажів або кредитного ризику на рівні окремого ліда чи позичальника. Банки і фінтех-компанії використовують його для оцінки кредитоспроможності, але та сама логіка працює і в B2B-продажах: модель оцінює кожен лід і дає менеджеру пріоритет: з ким варто говорити першим, бо ймовірність закриття угоди найвища. У продажах ті самі підходи працюють як методи прогнозування продажів: модель оцінює ймовірність закриття угоди, очікувану суму, ризик перенесення дедлайну і пріоритетність ліда для менеджера.
Аналітики даних жартують, що 80% їхньої роботи – це очищення даних, і 20% – скарги на очищення даних. За цим жартом стоїть реальна структура процесу: чотири етапи, де найдовший і найнудніший – підготовчий.
Найпоширеніша проблема на цьому етапі – дані є, але вони розпорошені між різними системами, зберігаються в різних форматах або мають пропуски. Саме тому побудова прогнозної моделі майже завжди починається з data engineering.
Алгоритм обирається під задачу. Коротко про основні:
| Алгоритм | Коли підходить | Типова задача |
|---|---|---|
| Linear/Logistic Regression | Проста залежність, мало змінних, потрібна інтерпретованість | Базовий прогноз виручки, скоринг |
| Random Forest/Gradient Boosting | Багато факторів впливу, нелінійні залежності | Прогноз попиту, churn, лід-скоринг |
| LSTM (нейронні мережі) | Складні часові ряди з довгою пам'яттю | Прогноз попиту, churn, лід-скоринг |
На практиці Gradient Boosting (зокрема XGBoost і LightGBM) закриває більшість бізнес-задач краще за все інше: він стійкий до шуму в даних, добре працює на середніх обсягах і дає зрозумілі пояснення, які ознаки найбільше вплинули на прогноз.
Модель навчається на частині даних – умовно, на 80% – і перевіряється на решті 20%, які вона не бачила. Це дозволяє зрозуміти, наскільки добре модель узагальнює закономірності.
Але для бізнес-моделей є нюанс: звичайне випадкове розбиття тут не підходить. Якщо навчати модель прогнозування продажів на даних за 2020-2024 роки, а тестувати на випадковій вибірці з того ж проміжку – модель може виглядати точною, але в реальності вона “підглянула” у майбутнє під час навчання. Тому для часових рядів завжди використовується хронологічне розбиття: навчання на ранньому періоді, тестування на пізнішому.
Після валідації модель виходить у продакшн, і починається постійний моніторинг: якщо поведінка ринку змінилась, точність моделі падає і її потрібно перенавчати.
Вибір інструменту залежить від трьох речей: де живуть ваші дані, який рівень технічної команди і який масштаб задачі. Немає найкращого стека, але є підходящий під конкретну ситуацію.
Базовий стек для більшості проєктів із машинним навчанням для бізнесу. Scikit-learn є бібліотекою з відкритим кодом, яка містить реалізації практично всіх класичних алгоритмів: від лінійної регресії до random forest і gradient boosting. Вона безкоштовна, добре задокументована і є стандартом у середовищі data science.
Поверх scikit-learn зазвичай додають XGBoost або LightGBM для задач на табличних даних і Prophet або statsmodels для часових рядів. Цей стек покриває 80% реальних бізнес-задач і не прив’язує до жодного хмарного провайдера.
Хмарні платформи мають сенс, коли задача виходить за межі одного ноутбука: потрібно навчати великі моделі, автоматизувати перенавчання, версіонувати моделі або розгортати їх як API для продакшн-систем.
Azure ML – логічний вибір для компаній, що вже використовують Microsoft-інфраструктуру: Power BI, Azure Synapse, Microsoft Fabric. Платформа орієнтована на простоту і швидкий старт, має drag-and-drop інтерфейс для менш досвідчених команд, але водночас підтримує повний код для data scientists.
Google Vertex AI – сильніший варіант, якщо дані вже в Google Cloud або BigQuery. Крива навчання тут крутіша, але платформа краще підходить для складних ML-пайплайнів і великих обсягів даних.
Окремий сценарій – коли прогнозна модель вже побудована, але результати потрібно зробити доступними для бізнес-користувачів без технічного бекграунду. Power BI дозволяє вбудовувати Python і R скрипти безпосередньо у звіти: модель запускається на бекенді, а менеджер бачить готовий прогноз у дашборді поруч із фактичними показниками.
Це рішення не для навчання моделей, але ідеальне для їх демократизації всередині компанії, коли кастомна розробка ML-моделей для бізнесу вже зроблена і потрібно інтегрувати результати в щоденну роботу команди.
Ось три проєкти, реалізовані командою IWIS, де прогнозна аналітика вирішувала конкретні бізнес-задачі.
Нові Продукти: прогноз виробництва слабоалкогольних напоїв
Група компаній “Нові Продукти” зіткнулась із класичною дилемою виробника: надлишкові залишки коштують грошей, дефіцит – частки ринку. Завдання полягало в тому, щоб прогнозувати попит достатньо точно для оптимізації виробничого плану.
Команда IWIS побудувала ML-модель на основі даних роздрібного споживання. Головним технічним викликом стала низька якість вхідних даних: у торгових точках не фіксувались нульові залишки, тому відсутність продажів неможливо було однозначно трактувати: товар закінчився чи просто не продавався? Для вирішення застосували методи апроксимації, що дозволили коректно інтерпретувати аномалії. Після серії ітерацій із різними ML-бібліотеками та архітектурами модель досягла точності прогнозування на рівні 80%.
Планета Кіно: модель відтоку клієнтів
Мережа кінотеатрів “Планета Кіно” поставила задачу знизити churn серед активних клієнтів. Команда IWIS проаналізувала транзакційну історію за понад рік, виділила кластери клієнтів зі схожою поведінкою і перевірила результати кластеризації через глибинні інтерв’ю з реальними відвідувачами – щоб переконатись, що математичні кластери відповідають реальним поведінковим патернам.
На основі кластерів побудували модель прогнозування відтоку, яка враховувала належність до кластеру як явний параметр. Після інтеграції моделі з CRM Salesforce Marketing Cloud і запуску комунікаційних ланцюжків під різні рівні ймовірності відтоку – показник churn знизився з 13% до 7%, а середній LTV клієнта зріс.
Edenred: управління портфелем B2B-клієнтів
Edenred потребував інструменту для раннього виявлення ризику відтоку в B2B-сегменті, де втрата одного контракту коштує набагато більше, ніж у роздрібі. Окремим викликом стала необхідність анонімізації клієнтських даних відповідно до вимог GDPR, оскільки обробка здійснювалась за межами юрисдикції ЄС. Команда запропонувала безпечний технічний підхід, що відповідав усім регуляторним вимогам. Результатом стала стабільно працююча churn prediction-модель, інтегрована у внутрішні процеси управління ризиками компанії.
Це питання, на яке рідко дають швидку відповідь, бо вона залежить від занадто багатьох змінних. Але можна окреслити логіку формування вартості.
Ціна складається з трьох компонентів: підготовка даних, розробка моделі, інтеграція і підтримка. На практиці підготовка даних часто стає найбільшим блоком роботи: data engineering, очищення, узгодження джерел і побудова pipeline можуть зайняти більше часу, ніж сама розробка першої версії моделі. Саме тому компанії, у яких вже є впорядкована BI-система як основа для прогнозної аналітики, стартують швидше і дешевше.
Починати з найамбітнішого сценарію є типовою помилкою. Набагато розумніше запустити пілот на одній задачі, отримати перший вимірюваний результат і вже на його основі ухвалювати рішення про масштабування. Так виглядає більшість успішних впроваджень, включно з кейсом “Нові Продукти”, де перша версія моделі була навмисно спрощеною, але дозволила виграти тендер і довести гіпотезу.
Якщо на більшість запитань відповідь позитивна, дані готові і можна рухатись до розробки.
Якщо ви хочете зрозуміти, яка задача має найбільший потенціал ROI у вашому бізнесі, і чи готові ваші дані до ML-моделювання – запишіться на безкоштовну консультацію. Ми розберемо вашу ситуацію та дамо конкретний висновок.